

Researchers have shown how to overcome a key limitation of the TabPFN foundation model AI tool and equip it to better handle geospatial data.
Whereas models such as ChatGPT have been built to deal primarily with text and data, TabPFN is used analyse and predict the outcomes of the kind of tabulated data (rows and columns) found in spreadsheets or databases.
The new work — described in a new paper published in the International Journal of Geographical Information Science — shows how the team from the University of Glasgow and Florida State University tested TabPFN’s ability to process and analyse geospatial data.
Geospatial data differs from many other kinds of data, in that each data point relates to others as indicators of physical locations in the real world.
The researchers found that TabPFN works well on many tasks related to geospatial data.
But it becomes less reliable on larger datasets, or when the relationships between nearby places are particularly localised.
Making connections between tabulated geospatial data
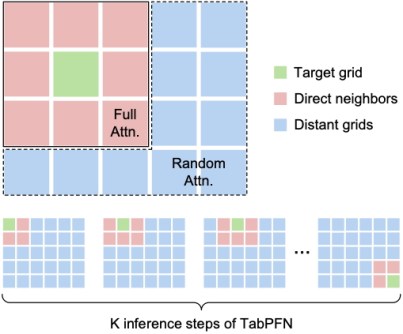
The team developed a new framework for TabPFN to use, based on a methodology they named Geospatial Sparse Attention (GSA).
The resultant modified, open-source tool, known as TabPFN-GSA, gives the model a ‘sense of place’ by focusing more of its attention on geographically relevant observations while still drawing on selected information from farther away.
“The first law of geography is that ‘everything is related to everything else, but near things are more related than distant things’,” said Dr Mingshu Wang of the University of Glasgow’s School of Geographical & Earth Sciences, and one of the paper’s authors.
We can scrutinise how closely data points are related to each other in space
“In geospatial data, that means that we can scrutinise how closely data points are related to each other in space in order to find connections and draw conclusions.”
“General-purpose tabular models can be very powerful, but they are trained to treat rows as independent observations — they don’t automatically understand the principles of geospatial data,” Dr Wang added.
“That’s why we set out to expand TabPFN’s ability to make the connections between tabulated geospatial data instead of trying to build and train a new model from scratch.”
Better context improves the model’s performance
The team determined how TabPFN reaches its predictions and developed GSA to intervene at the point of inference, where it makes its predictions based on its understanding of the data.
By studying the model’s internal attention patterns, they found that its focus became increasingly concentrated on a small number of observations as it worked, and on geographically closer ones.
“In geospatial data, each row of the table has its own locational information like map coordinates,” said the paper’s first author, University of Glasgow PhD student, Rui Deng.
“In our Geospatial Sparse Attention model, we divide the whole region covered by the table into a grid, so we know the relative distance between all the data points.
We guide the model to attend more to nearer points rather than distant ones
“Then, we guide the model to attend more to nearer points rather than distant ones, focusing it on the local context.
“We didn’t modify TabPFN itself; instead, we provided it with a better context to improve the model’s performance.”
Geospatial Sparse Attention for more accurate and robust predictions
The researchers first tested TabPFN-GSA’s performance on 30 synthetic datasets representing a range of geographical processes.
Then, they set it to work on four real-world datasets span a wide range of scale, from just over 1,000 records to roughly 70,000:
- Air-pollution readings;
- County-level results from the 2020 US presidential election;
- Housing prices; and
- Neighbourhood-level poverty across the continental United States.
The team chose these datasets as a benchmark to help determine the effectiveness of their GSA model, as they had previously been used in other geospatial data research projects.
They found that TabPFN-GSA generally produced more accurate and robust predictions than the standard model, and reduced the memory failures that prevented the original from running on the largest datasets.
Significantly, it was able to complete predictions on the 70,000-row poverty dataset, which the unmodified model could not handle.
Handling larger datasets
The researchers expect that TabPFN-GSA, which is freely available as open-source software, will be useful to data science researchers in a wide range of contexts, from academia to local councils, national agencies and data-analytics companies.
And since TabPFN-GSA can be used offline on local computers, it could help ensure that sensitive data can be processed without the security concerns associated with online AI models.
“Foundation models are designed to generalise across many datasets, but geographical data contain distinctive structures that general-purpose models may overlook,” said Dr Ziqi Li, a co-author of the paper from Florida State University.
“This study shows that established geographical principles can be incorporated into a pre-trained foundation model in a lightweight and practical way, improving both its spatial awareness and its ability to handle larger datasets.”
The team’s paper, ‘Do Foundation Models Work for Geospatial Tabular Data? An Investigation of TabPFN and a Proposed Enhancement based on Geospatial Sparse Attention,’ has been published in the International Journal of Geographical Information Science.
The data and code are available in the figshare repository. TabPFN-GSA is available in a public Python repository.


